房价数据转换和清洗
本文共 6295 字,大约阅读时间需要 20 分钟。
1.下载厦门房价信息源文件
下载链接: 密码:e1fg
2.新建一个ipynb文件
下载成功后,在源文件所在的文件夹中下图所标示的位置中输入cmd,确定命令正确后运行。
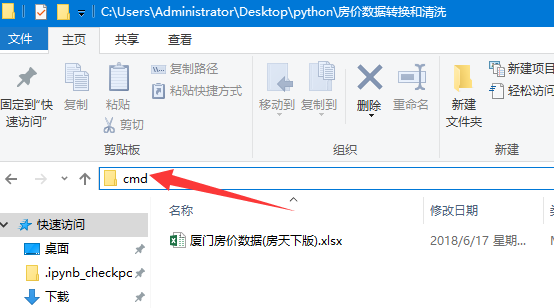
打开cmd.png

cmd打开后图示.png
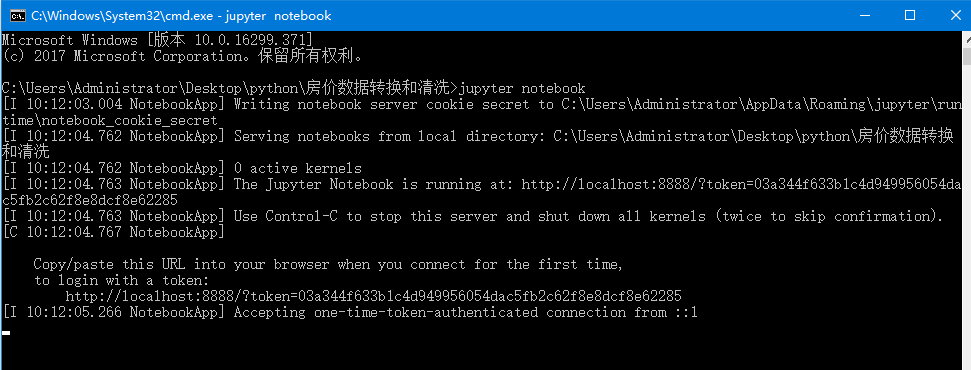
运行命令成功图示.png
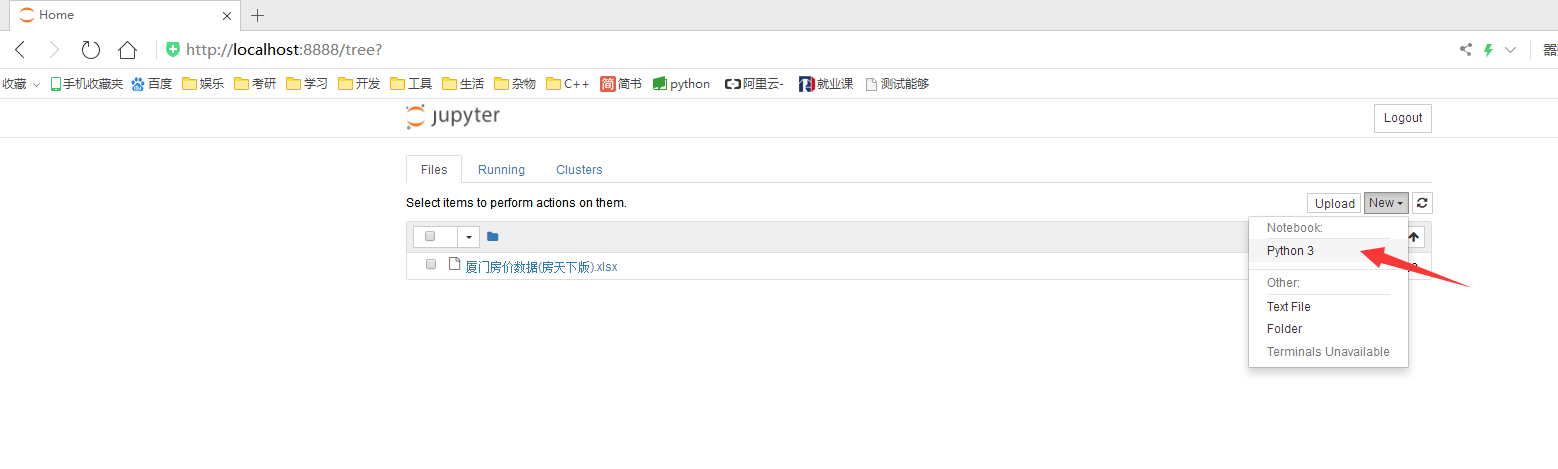
新建一个ipynb文件.png
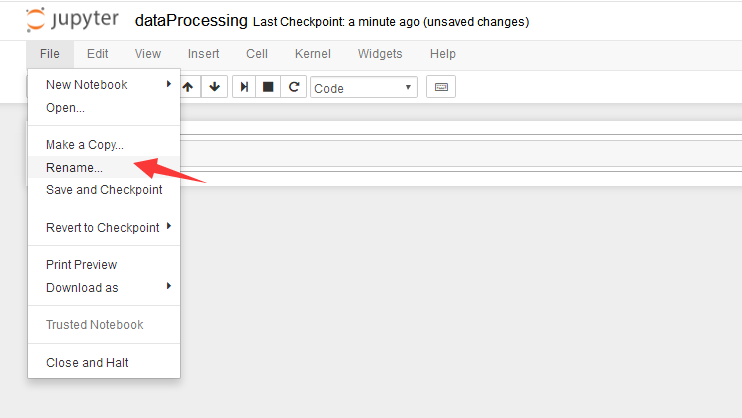
对新建的ipynb文件重命名1.png
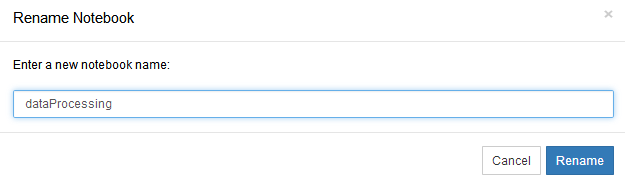
对新建的ipynb文件重命名2.png
3.导入数据并查看数据字段
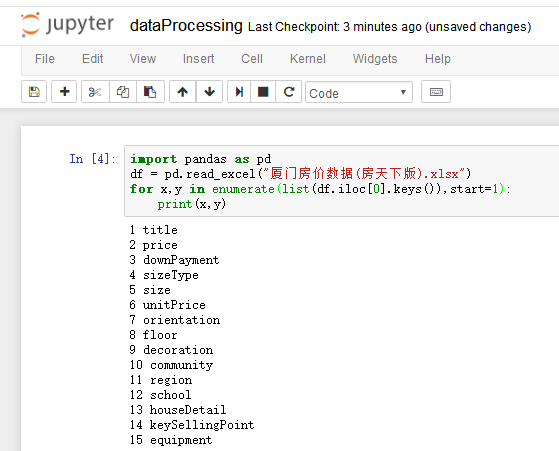
导入数据.png
从上图可以看出原有共15列,分别为:标题title、价格price、首付downPayment、户型sizeType、面积size、单价unitPrice、朝向orientation、楼层floor、装修decoration、社区community、区域region、学校school、房屋详情houseDetail、核心卖点keySellingPoint、配套设施equipment。
4.数据处理
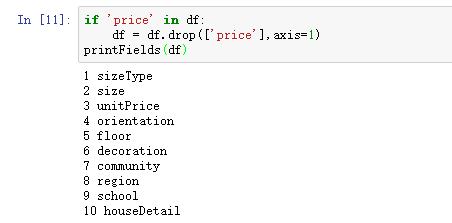
因为这次实验不用到文本识别和语义分析,去除标题title、核心卖点keySellingPoint、配套设置equipment三个字段。
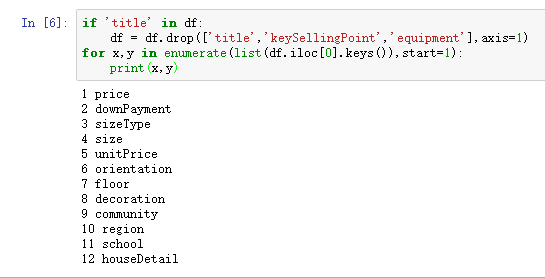
数据处理1.png
在数据处理过程中,需要多次查看DataFrame的字段,所以定义一个函数。
def printField(df): for x,y in enumerate(list(df.iloc[0].keys()),start=1): print(x,y)
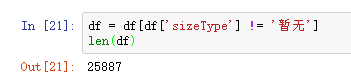
观察数据源,发现首付downPayment字段与价格price字段成线性关系,所以要去除这个字段。
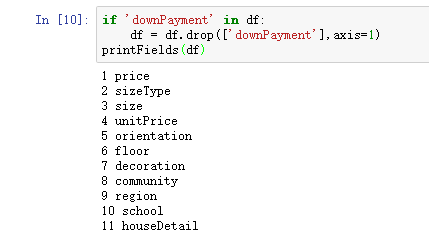
数据处理2.png
数据处理3.png

选出满足条件的行.png
数据处理4.png
把户型拆分成3个字段:室、厅、卫,以下一段代码新产生一个DataFrame保存新产生的3个字段
import pandas as pdimport resizeType_list = []def findNumber(reStr,sourceStr): result_list = re.findall(reStr,sourceStr) if len(result_list): return result_list[0] else: return 0for i in range(len(df)): sizeType = df['sizeType'].iloc[i] sizeType_dict = dict( room = findNumber('([0-9]*)室',sizeType), hall = findNumber('([0-9]*)厅',sizeType), restroom =findNumber('([0-9]*)卫',sizeType) ) sizeType_list.append(sizeType_dict)df1 = pd.DataFrame(sizeType_list,columns=sizeType_list[0].keys()) 下面的图把3个字段赋值给原来的DataFrame,并显示一下前面10行
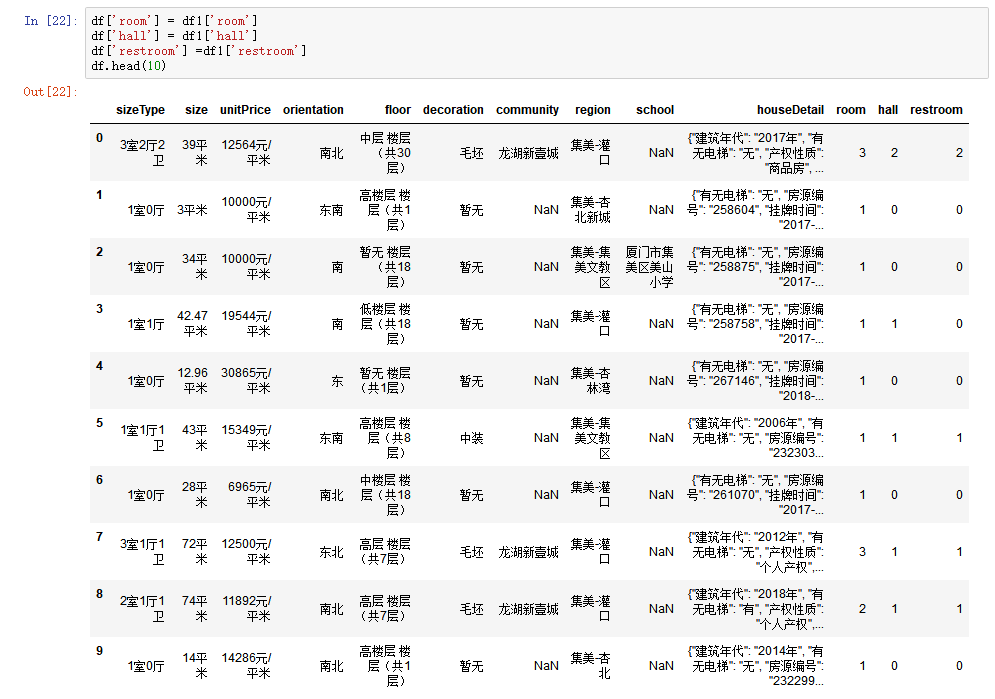
增加3个字段.png

删除sizeType字段.png
删除size字段中的平米,使该字段内容变为数字内容

处理数据6.png
删除unitPrice字段中的元/平米,使该字段内容变为数字内容
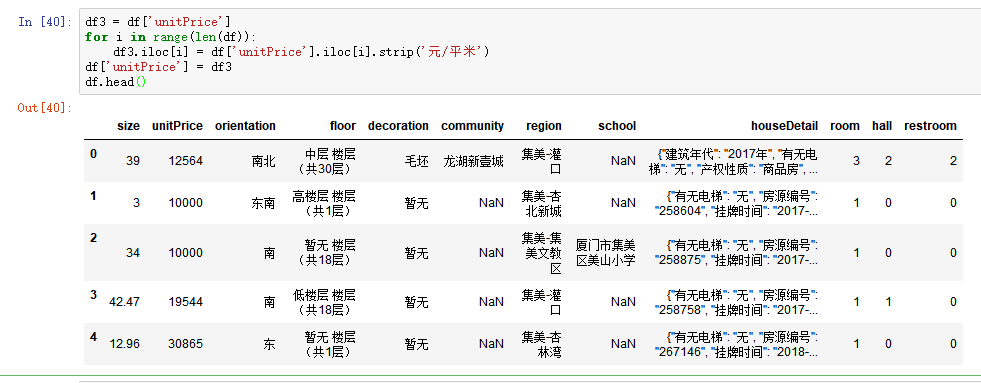
处理数据7.png

查看是否有异常值.png

查看异常值情况.png
删除这两个异常值
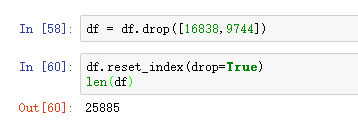
删除这两个异常值.png
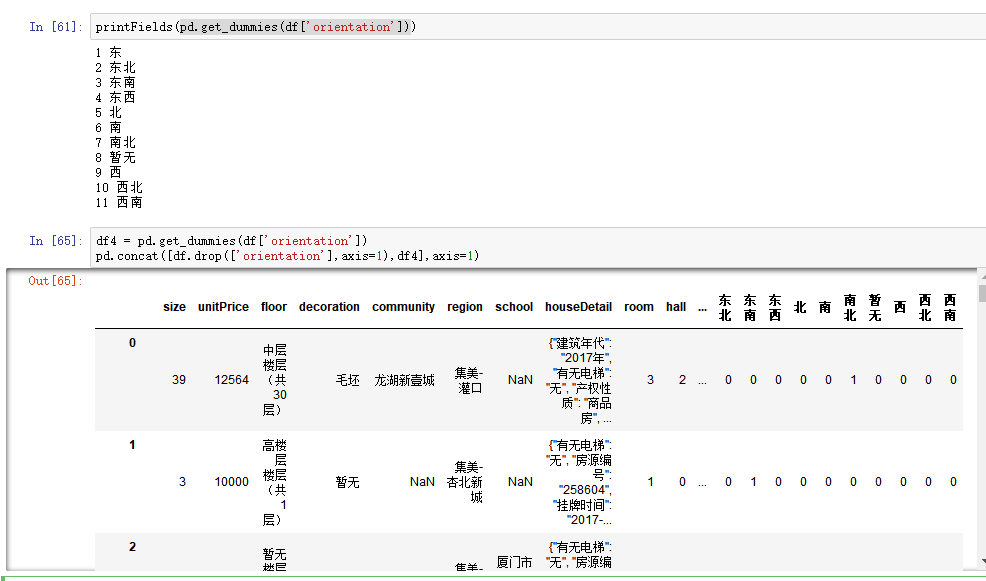
处理数据8.png
作者发现后面一些字段的处理相对来说比较麻烦,所以经过一段时间的抉择,统一用函数产生新的DataFrame,然后把新的DataFrame用pd.concat方法连接起来,这样编写代码时逻辑更清晰。所以前面的篇幅可以用作思路的参考,最终数据处理只需要复制下面一段代码就可以完成。
'''原来的数据总共有15列:分别为:标题title、价格price、首付downPayment、户型sizeType、面积size、单价unitPrice、朝向orientation、楼层floor、装修decoration、社区community、区域region、学校school、房屋详情houseDetail、核心卖点keySellingPoint、配套设施equipment''''''进行简单的房价预测不需要用到文本识别和语义分析,因此不需要用到title、keySellingPoint、equipment,根据现实的情况来说因为先有单价才有总房价,而进行预测的正是单价,所以用不到price、downPayment。观察房屋详情,发现其中的数据有错误,有的20多层的楼房却显示没有电梯,这不符合高层住房电梯规定,7层及以上住房必须安装电梯,不符合实际,所有房产有无电梯根据总楼层数判断'''import pandas as pdimport reimport timedef getSizeType(df): def findNumber(reStr,sourceStr): result_list = re.findall(reStr,sourceStr) if len(result_list): return result_list[0] else: return 0 sizeType_list = [] for i in range(len(df)): sizeType = df['sizeType'].iloc[i] sizeType_dict = dict( room = findNumber('([0-9]*)室',sizeType), hall = findNumber('([0-9]*)厅',sizeType), restroom =findNumber('([0-9]*)卫',sizeType) ) sizeType_list.append(sizeType_dict) return pd.DataFrame(sizeType_list,columns=sizeType_list[0].keys())def getSize(df): df1 = df['size'].copy() for i in range(len(df)): size = float(df['size'].iloc[i].strip("平米")) if size < 50: df1.iloc[i] = 'size1' elif size < 100: df1.iloc[i] = 'size2' elif size < 150: df1.iloc[i] = 'size3' elif size < 200: df1.iloc[i] = 'size4' else: df1.iloc[i] = 'size5' return pd.get_dummies(df1)def getUnitPrice(df): df1 = df['unitPrice'].copy() for i in range(len(df)): df1.iloc[i] = df['unitPrice'].iloc[i].strip("元/平米") return df1def getOrientation(df): return pd.get_dummies(df['orientation'])def getHeight(df): df1 = df['floor'].copy() for i in range(len(df)): df1.iloc[i] = df['floor'].iloc[i].split(' ')[0][0] return pd.get_dummies(df1)def getElevator(df): ele_list = [] for i in range(len(df)): str1 = df['floor'].iloc[i].split(' ')[1] allFloor = int(re.findall("共(.*)层",str1)[0]) elevator = 1 if allFloor >= 8 else 0 ele_dict = {'elevator':elevator} ele_list.append(ele_dict) df1 = pd.DataFrame(ele_list) return df1def getDecoration(df): df1 = df['decoration'].copy() for i in range(len(df)): df1.iloc[i] = df['decoration'].iloc[i].strip('修') return pd.get_dummies(df1)def getCommunity(df): df1 = df['community'].copy() for i in range(len(df)): df1.iloc[i] = 1 if df['community'].iloc[i] == \ df['community'].iloc[i] else 0 return df1def getDistrict(df): df1 = df['region'].copy() for i in range(len(df)): df1.iloc[i] = df['region'].iloc[i].split('-')[0] return pd.get_dummies(df1)def getRegion(df): df1 = df['region'].copy() for i in range(len(df)): region = df['region'].iloc[i].split('-')[1] df1.iloc[i] = region.strip('(').strip(')') return pd.get_dummies(df1) def getSchool(df): df1 = df['school'].copy() for i in range(len(df)): df1.iloc[i] = 1 if df['region'].iloc[i] == \ df['region'].iloc[i] else 0 return df1def cleanFloor(df): for i in range(len(df)): if '共' not in df['floor'].loc[i]: df = df.drop([i]) df = df.reset_index(drop=True) return dfdef cleanSizeType(df): for i in range(len(df)): if '室' not in df['sizeType'].loc[i]: df = df.drop([i]) df = df.reset_index(drop=True) return dfdef cleanCommunity(df): df = df[df['community'] == df['community']] df = df.reset_index(drop=True) return dfif __name__ == "__main__": startTime = time.time() df = pd.read_excel("厦门房价数据(房天下版).xlsx") df = cleanCommunity(df) df = cleanFloor(df) df = cleanSizeType(df) #下面几个字段是列数较少的字段 unitPrice = getUnitPrice(df) sizeType = getSizeType(df) elevator = getElevator(df) community = getCommunity(df) school = getSchool(df) #下面的字段是通过get_dummies方法产生的9-1矩阵,列数较多 orientaion = getOrientation(df) height = getHeight(df) size = getSize(df) decoration = getDecoration(df) district = getDistrict(df) region = getRegion(df) df_new = pd.concat([unitPrice,sizeType,elevator,community,school,\ orientaion,height,size,decoration,district,region],\ axis=1) df_new.to_excel("数据处理结果.xlsx",columns = df_new.iloc[0].keys()) print("数据处理共花费%.2f秒" %(time.time()-startTime)) 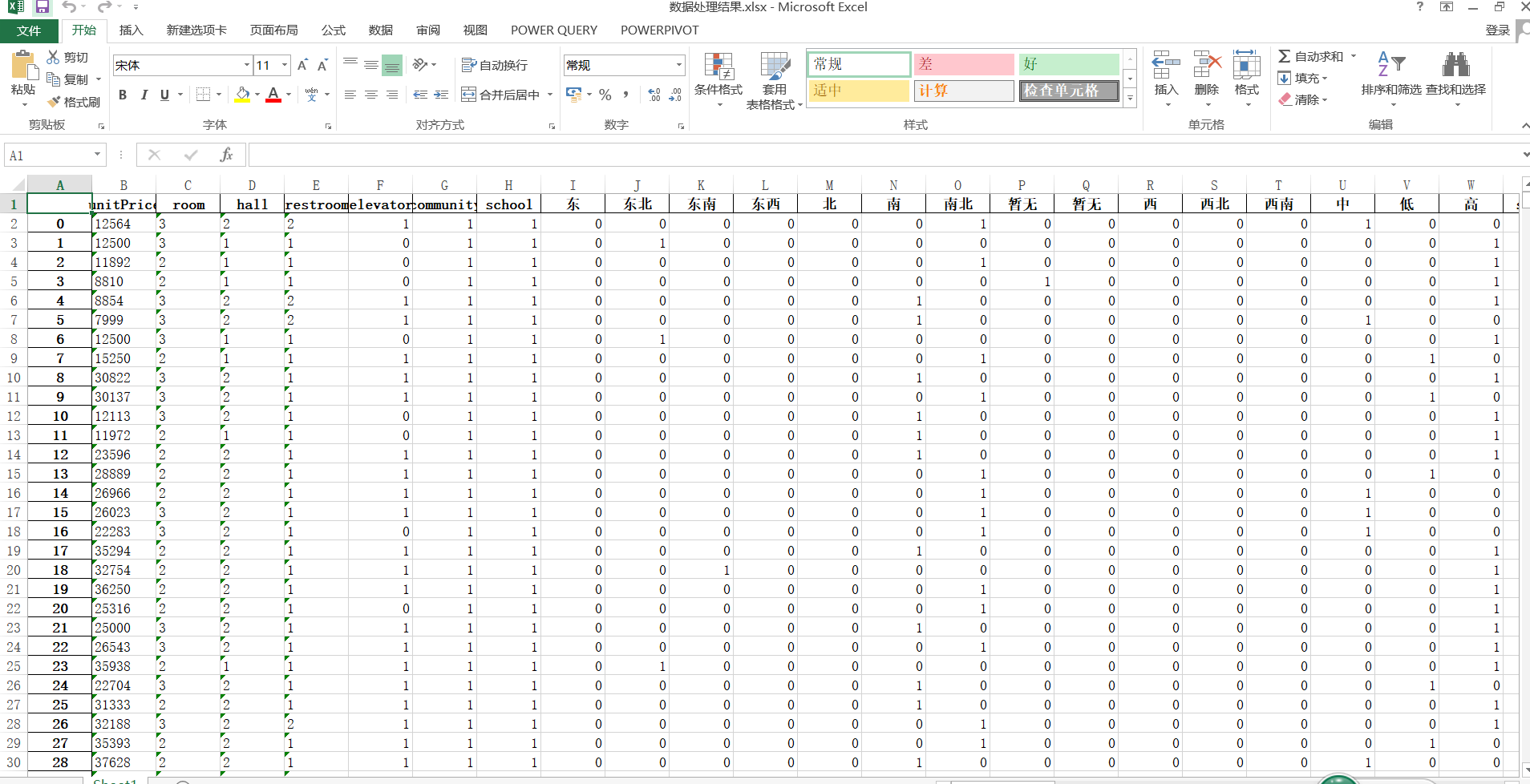
数据处理结果图示.png
转载地址:http://xzmol.baihongyu.com/
你可能感兴趣的文章
【LaTeX排版】LaTeX纸排版<两>
查看>>
C/C++函数调用方式
查看>>
Timer Swing
查看>>
Cassandra命令行CLI的基本使用
查看>>
Java String常见问题
查看>>
x264代码剖析(十五):核心算法之宏块编码中的变换编码
查看>>
Android仿微信进度弹出框的实现方法
查看>>
Spring事务管理
查看>>
[转]所有人都在渲染程序员的中年危机,我们却在劝你重新学会学习
查看>>
oom killer
查看>>
10.Django ModelForm
查看>>
MXNET:卷积神经网络基础
查看>>
UIPageViewController 翻页、新手引导--UIScrollView:pagingEnabled
查看>>
[五]基础数据类型之Short详解
查看>>
ILOG Gantt 3.0 注册机
查看>>
自己实现几个基本函数
查看>>
谨防沦为DLL后门木马及其变种的肉鸡
查看>>
C#构造函数的重载
查看>>
Silverlight4.0教程之轻松操作剪切板
查看>>
GIF, JPEG和PNG
查看>>